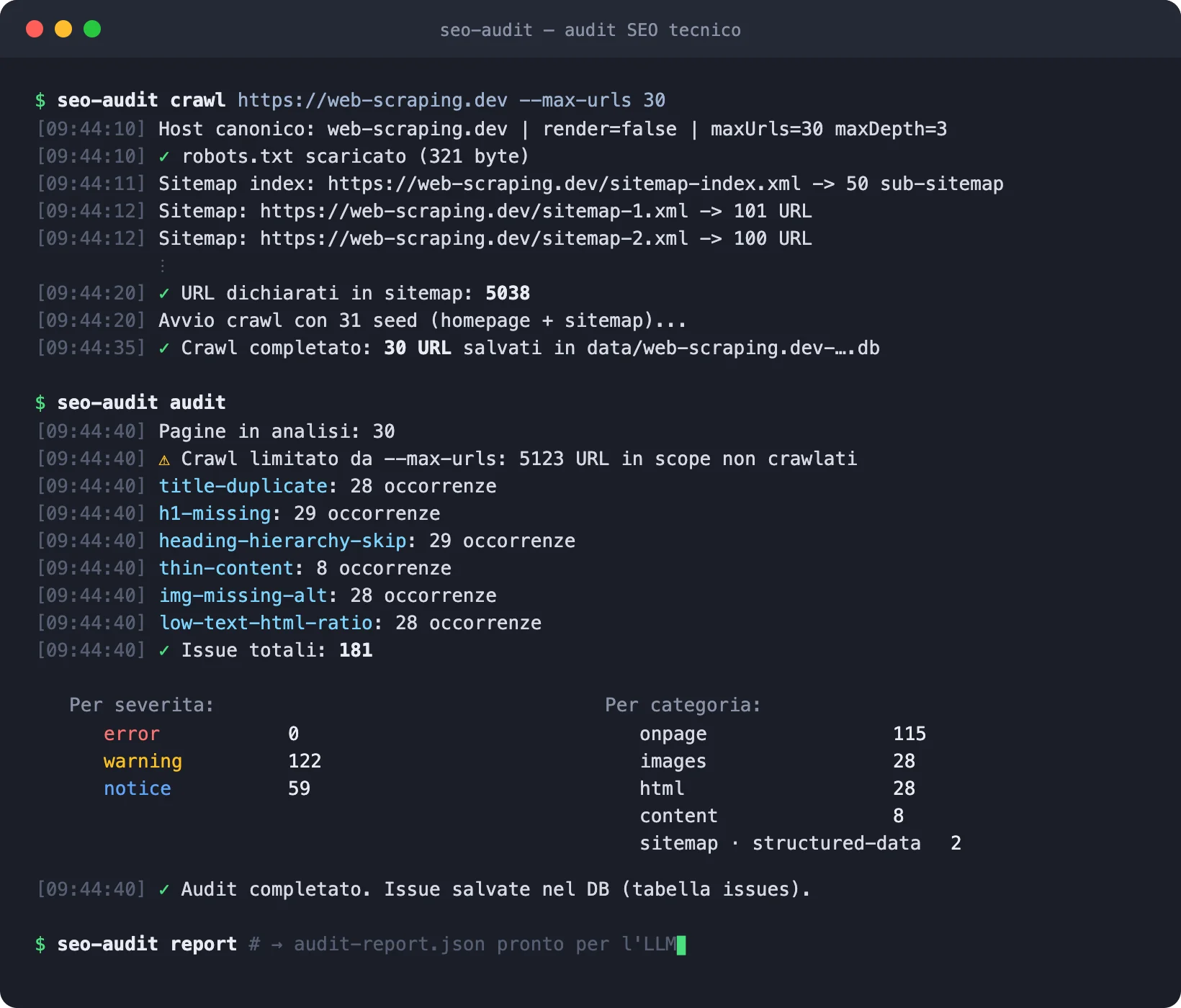
Quando lanci un site audit con Semrush, Screaming Frog o Ahrefs, cosa succede davvero sotto il cofano? Meno di quanto pensi: la maggior parte di un audit tecnico non ha niente di proprietario. È crawling più regole deterministiche. Codice che si può scrivere.
Così l'ho scritto. In questo articolo ti racconto cosa ho imparato ricostruendo un site audit da zero: dove i tool a pagamento valgono i soldi che costano, e dove no.
Cosa è proprietario e cosa no
Partiamo dalla distinzione onesta, perché senza questa l'articolo sembrerebbe uno spot. I grandi tool SEO hanno tre asset che non si possono replicare:
- I backlink: servono anni di crawling del web intero. Nessuno se li ricostruisce in casa.
- I volumi di ricerca: dati che arrivano da fonti proprietarie e clickstream.
- Il SERP tracking: infrastruttura per interrogare Google su scala.
Tutto il resto, la parte tecnica on-site dell'audit, dipende solo da due ingredienti: un crawler che visita il tuo sito, e un motore di regole che valuta quello che trova. Status code, redirect, canonical, sitemap, meta tag, heading, link interni, immagini, hreflang, structured data, contenuti duplicati. Persino le Core Web Vitals, che Google misura con Lighthouse: open source.
Le 11 famiglie di controlli di un audit tecnico
Ricostruendo i check uno per uno, ho finito per organizzarli in 11 categorie. Tre meritano un approfondimento, perché nascondono più sostanza di quanto sembri:
Status e redirect. I 404 e i 500 li vedono tutti. Più interessanti le catene di redirect (A→B→C: ogni hop disperde segnale e rallenta il crawl di Google) e i loop.
Indicizzabilità. Qui c'è il concetto più frainteso della SEO tecnica: una pagina non è "indicizzabile" perché risponde 200. Il verdetto vero combina quattro segnali: status code, meta robots, header X-Robots-Tag e canonical. Una pagina 200 con canonical verso un altro URL è, di fatto, fuori dall'indice. Un audit serio deve incrociarli tutti e quattro, e poi cercare le contraddizioni: pagine noindex linkate da tutto il sito, canonical che puntano a pagine che non esistono, robots.txt che blocca pagine che vorresti indicizzate.
Confronto sitemap ↔ crawl. Il controllo più sottovalutato in assoluto. La sitemap dichiara le pagine che vorresti far trovare; il crawl scopre quelle raggiungibili dai link. La differenza tra i due insiemi è una miniera:
- in sitemap ma mai linkate → pagine orfane (esistono, ma nessun percorso interno ci arriva: per Google valgono pochissimo)
- linkate ma non in sitemap → contenuto che non stai dichiarando
Le altre otto famiglie (on-page, contenuti, structured data, hreflang, immagini, link, HTML di base, sicurezza) sono i check che ti aspetti: le trovi elencate nella documentazione del tool.
Nessuno di questi controlli richiede dati esterni. Tutti richiedono rigore: è qui che si gioca la differenza tra un audit e una lista di lamentele.
L'ho validato contro Semrush, check per check
Costruire un tool è facile. Costruirne uno di cui fidarsi no. Così ho preso un sito reale di cui avevo il report Semrush completo (un sito di servizi locali, circa 1.100 pagine indicizzabili) e ho confrontato i risultati controllo per controllo.
Sui check confrontabili, i numeri combaciavano. In diversi casi al pezzo esatto: stessi 10 link interni nofollow, stessi 2 H1 mancanti, stessa segnalazione sulla sitemap assente dal robots.txt. Dove divergevano, il motivo era quasi sempre la copertura: il mio crawl analizzava l'intero sito, il report che avevo a disposizione si fermava a un campione di ~100 pagine. Su quel sito, andare a fondo ha fatto emergere cose che il campione non vedeva: più di 100 pagine orfane e una manciata di vecchi URL in redirect 301 ancora linkati da ogni pagina del sito.
Su un secondo sito, il tool ha trovato il mio caso preferito: il robots.txt dichiarava una sitemap che rispondeva 404. E il percorso standard /sitemap.xml? Un redirect... verso lo stesso 404. Il sito non aveva una sitemap funzionante, e nessuno se n'era mai accorto.
Gli errori istruttivi (i miei)
La parte più utile della validazione sono stati i falsi positivi del mio stesso tool, perché ogni bug era una lezione di SEO tecnica:
- Segnalavo come "loop di redirect" quella che era una banale catena A→B→C. Un loop esiste solo se un URL si ripete nel percorso. Sembra ovvio; scritto in codice, non lo era.
- Segnalavo
Locksmithcome tipo schema.org sconosciuto. È un sottotipo legittimo di LocalBusiness. Le tassonomie di schema.org sono più profonde di quanto qualunque lista "dei tipi principali" faccia credere. - Trattavo
sitemap.xmlcome una pagina senza title e senza H1... perché il server la serviva con content-typetext/html. I server mentono: un audit deve difendersi anche da questo.
Scrivere le regole ti costringe a definire esattamente cosa significa ogni controllo. È il miglior corso di SEO tecnica che abbia mai fatto.
Il report che finisce in pasto all'AI
La scelta di design di cui sono più contento: il tool non produce un PDF con i grafici, produce un file JSON completo, senza troncamenti, pensato per essere letto da un LLM.
Il flusso: crawl, audit, report. Poi passi il JSON a Claude o ChatGPT con un prompt tipo "sintetizza i problemi per priorità di impatto e stimane lo sforzo di fix". La parte meccanica (trovare i problemi) la fa il codice, deterministico e verificabile; la parte di giudizio (cosa conta davvero per questo sito) la fa il modello, ed è bravissimo, a patto di dargli dati completi invece che screenshot.
Il report include anche i suoi stessi limiti: se il crawl è stato troncato, il JSON lo dichiara, così l'AI non spaccia per completo un audit parziale.
Prova il tool (o fatti fare l'audit)
Il tool si chiama audit-seo-tecnico: open source, licenza MIT, gira in locale sul tuo computer: i dati del tuo sito non passano da nessun server.
Se mastichi il terminale, ti basta Node.js:
npx audit-seo-tecnico crawl https://tuosito.it
npx audit-seo-tecnico audit
npx audit-seo-tecnico report
Il codice, la documentazione e le istruzioni complete sono su GitHub. Se lo provi e trovi un check che sbaglia, aprimi una issue: metà dei controlli migliori è nata correggendo errori.
E se il terminale non fa per te: l'audit tecnico sul tuo sito lo faccio io, gratis, fino a 30 pagine. Sotto il cofano gira lo stesso motore, ma in una versione ridotta per esigenze tecniche: sul sito il crawl gira dentro una funzione web con un tempo massimo di esecuzione, quindi pagine e profondità sono limitate e i controlli più lenti (come il probe dei link esterni) restano disattivati. La versione da terminale non ha questi vincoli. Il report web arriva comunque in italiano semplice, con le priorità già ordinate, e il lavoro di interpretazione ce lo metto io.
P.S. L'ho lanciato anche su questo sito, ovviamente. Unico appunto: rapporto testo/HTML basso, il prezzo di fare siti in React. Nessuno è perfetto.